为什么 ARM 版 Mac 运行效率很高?
AR 185 2023-10-01ARM 和英特尔版本的 Mac 本质不同;运行效率高只是表象,实质原因是多芯片各司其职。
本文中,我将以从 ARM 与 x86 芯片在 Mac 中使用方式的区别开始,探讨 ARM 版 Mac 应用的运作方式。在开始之前,先明确几个事实:
- 至今为止 Apple 并未展示任何 ARM 版 Mac 芯片
- ARM 版 Mac 会采用自研 GPU
- iOS 应用不可运行在任何英特尔芯片的 Mac 上
我们先从现有所有型号的 Mac 电脑说起。无论是产品线里最小号的 Mac Mini,还是性能最强的 Mac Pro,基本都具备如下芯片。
一颗英特尔的多核心处理器 + 一颗性能比较强的显卡(英特尔的 IRIS,AMD 的 Navi,或者早期英伟达的显卡) + Apple 的 T2 芯片。其中 CPU 负责逻辑运算,GPU 具备超多核心并行处理图形内容,T2 负责安全和存储管理。在这套逻辑中,CPU 和 GPU 分别具备自己的存储区域,互不相干。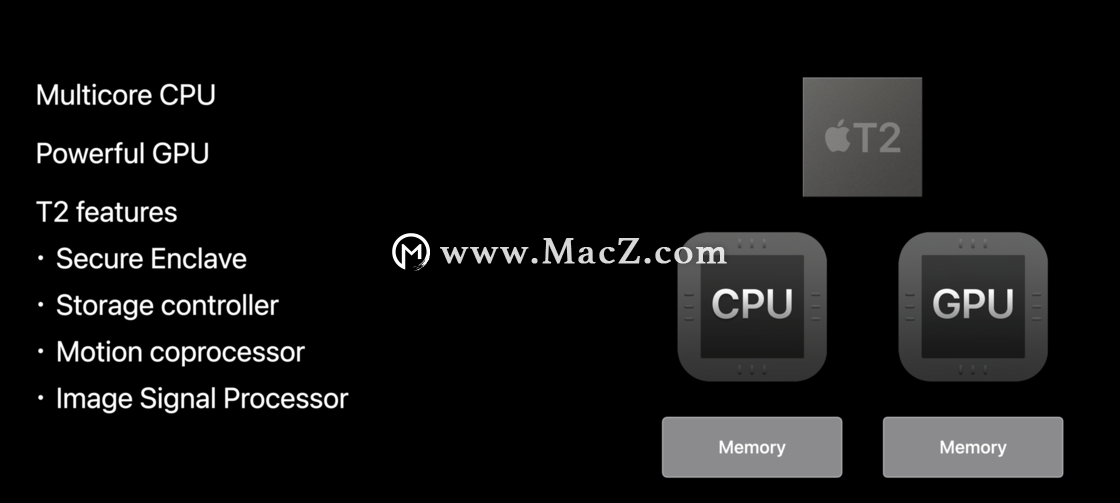
以常见的视频渲染工作流为例:当你往时间轴上加复杂的特效时,CPU 会用掉大部分算力来进行特效运算;当视频加码或解码时,则需要牺牲掉 CPU 的一部分算力来软解,或使用部分 CPU 上搭载的额外硬件来进行硬解码;当你要将这些特效渲染到一个完整视频以便导出时,GPU 便利用自身多核心并行运算的优势来负责渲染工作。
在操作系统运作时,T2 上的安全模块负责处理用户身份的验证,Apple Watch 手表解锁之类的安全事务。它的运作机理是自己根据一个独特的只读密码来生成可用的验证信息,经过安全处理后来判断其它设备是否使用同一个账户登录。当然 T2 还负责一些别的事情,比如硬盘加密和 APFS 系统存储区块只读处理,防止恶意软件修改系统代码。

CPU,GPU 和 T2 这三个芯片太过分散,且架构不同,直接后果是互相之间能交流的信息有限。那有没有更好的解决方案,让它们能协同起来做事,被统一调度,在同一时间内能一起处理共有信息?答案是有的,这个方案叫做 SoC 片上系统,也就是手机芯片用了十来年的技术。
它的核心思想便是整合,即把所有东西都放在一起。这样芯片只需要用最好的工艺生产一遍,而不是更具不同厂商的进度将 3 个不同的东西用不同的工艺生产好然后拼在一起。比如近年来英特尔的 CPU 工艺就在拖后腿,性能无法提升的情况下发热还很大。倘若 CPU,GPU,T2 集成在一起使用最新工艺,既能移除没必要的生产成本,还能大幅提高效能,一举两得。

于是乎 Apple 提出了自己 ARM 版 Mac 新品的结构图,也就是上图。这次芯片换代, Apple 不仅处理掉了第三方的 CPU,且一并处理掉了第三方的 GPU。仔细观察,你会发现这个片上系统除了 CPU 与 GPU 之外,还包含了许多其它的重要模块。首先 T2 不需要在单独放一颗芯片,将安全模块整合进来即可。接着将高性能的显卡整合进来,高性能的统一访问存储整合进来,满足未来需求的神经网络运算模块整合进来。加密加速模块,视频独立硬解模块,内核保护模块,能耗管理模块,HDR 显示支持模块,视频播放模块全给它放进来。这样的规划是之前的因特尔架构下不可能做到的,即不方便加新的硬件,也不可能做硬件间整合。
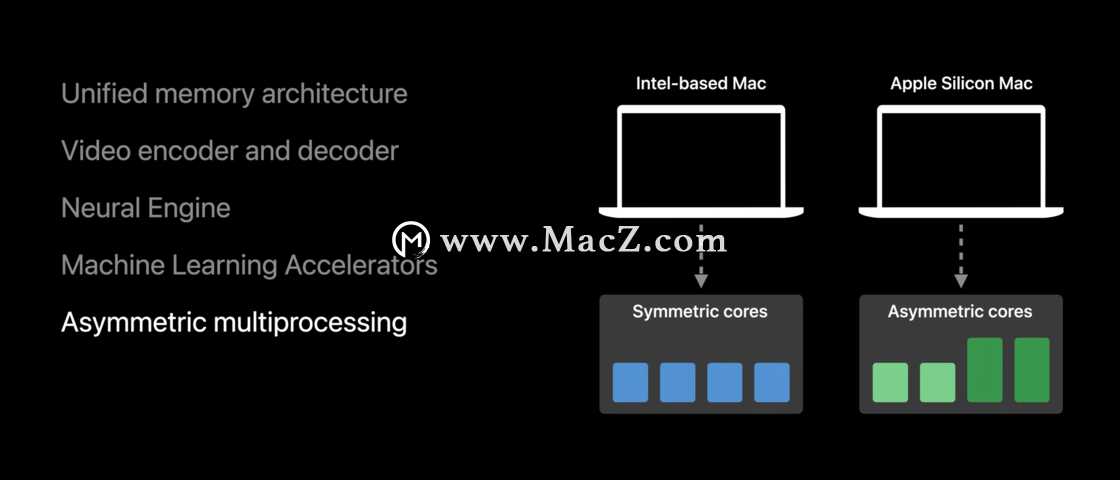
那么很多人好奇的为什么 fcpx 可以在 A12Z 上跑三路 4K ProRes 视频,正是因为这里负责视频解码的不是 CPU,也不是 GPU,而是 A 系列芯片里独立的视频编码硬件模块。这个模块和 Apple 放在自己 Mac Pro 上的那个用于 ProRes RAW 加速的 Afterburner 卡设计思路类似。
说完了视频解码,你也许会问这个 A 系列芯片里的 CPU 和传统的 x86 CPU 有什么区别?在传统的多核心处理器中,各个处理器的能力是非常接近的。比如英特尔的四核处理器,可以类比成四个能力相当的克隆人。
而在 ARM 芯片中,设计则有很大区别,ARM 架构中的 CPU 分为性能核心和低功耗核心。这里注重能耗指的并不是为了省电而牺牲性能,而是指需要多少性能付出多少劳动,不要杀鸡用牛刀(空费电)。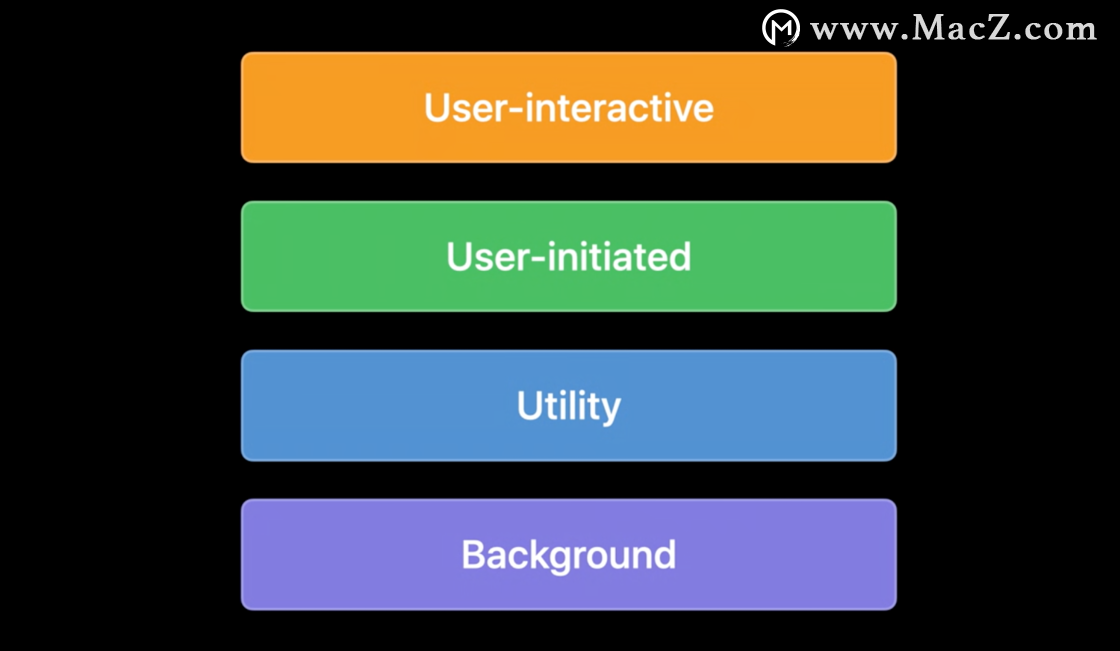
为了解决这个按劳分配的难题, Apple 采用的是 GCD 的 QOS 逻辑。你可以把 GCD 理解成一个包工头,手下指挥着性能核心和低功耗核心,为其分派任务。QOS 则是开发者定义的性能指标,比如开发者说这个东西是用户点击正在操作的内容,需要尽快给出结果,便会将 QOS 设置为 UI 级。此时 GCD 分派任务时看到开发者要求的 QOS 是 UI 级,便会将任务分配到高性能核心上尽快完成。
反之若开发者不急着要,也可以把 QOS 设置为后台级。这时候 GCD 分工时就会看到开发者不急着要这里面的结果,因此若需要省电时则这部分内容可以放在低功耗核心上运算。若有其它更紧要的任务则可以把低优先级的任务先缓一缓,紧着最着急的来。

说完了 ARM 在 CPU 运算上的区别,我们来聊聊内容显示。最近新闻中一个常见的误解便是把 Rosetta 翻译后的图像效能也当作被折损的效能,其实不然。罗赛塔翻译器本质上来说是个指令集翻译器,在把 x86 指令集的内容翻译到精简指令集时确实有性能折损,但这个折损和图形显示没有一点关系。
当计算机需要 GPU 来处理图形运算时,我们需要用一种特殊的语言来和显卡沟通,这个语言我们叫做图形框架。大家所熟知的图形框架可能有微软的 DirectX,开源的 OpenGL 和 Apple 自家的 Metal 框架都属其中。即便是被翻译后的应用,也会直接调用 Metal 指令对显卡做出访问,因此没有图形性能折损。 Apple 过去五年始终喊着让开发者尽快使用跨平台 Metal 框架,除平台统一性考量外,便也在为这次转型做准备。

处理器和显卡大家比较熟悉,接下来我们来看看大家不那么熟悉的机器学习与神经网络硬件模块。机器学习的理论基础是神经网络,科学界的大牛提出一系列神经网络模型,在大量数据(大数据)的基础下进行训练,得到的结果是一个可用的机器学习模型。这个过程中有两个点值得关注。第一个是神经网络训练的效率,第二个是得到模型之后放进新数据进行预测的效率。训练好的模型还可能根据用户需求进行强化学习,因此保证机器学习能力的芯片就变的至关重要。
在过去,这些训练大多是在处理器或显卡上完成的。一心不易二用,这些硬件终究不是做这件事的最佳载体,因此便有了专用模块。你也许会好奇,这些东西与我们有什么关系呢?事实上,机器学习和神经网络可能是接下来几年最重要的发展方向之一。
当我们的手表在判断我们是否进入梦乡时,用的是机器学习运动感知训练的结果;当我们在 iPad 上用铅笔做出手写识别时,我们用的是机器学习视觉训练的结果;当我们做语音同声翻译时,我们用的是声学辨识训练的结果。如此种种,均需要片上系统上独立芯片的支持。

上文中我们说完了 ARM 的芯片核心,接下来我们将目光放在软件上。要了解其性能表现,我们需要对它们的运行方式做个区分。在 ARM 版的 Mac 上,软件有如下运作方式:
所有 Apple 自家应用,包括系统本身以 ARM 原生模式运行,无任何性能折损;所有 iOS 和 iPadOS 应用,以 ARM 原生模式运行,无任何性能折损;所有虚拟机应用,运行在 Big Sur 提供的虚拟机环境下;所有 Catalyst 应用,需重新编译为 Universal 应用,无任何性能折损;
所有 32 位 x86 应用,已在三年前被 Apple 淘汰,无法运行;所有 64 位 x86 应用,若以应用商店分发,则下载的便是已翻译版本;所有 64 位 x86 应用,若在网络上下载安装,则在安装时翻译;所有 64 位 x86 应用,若以拖拽形式安装,则在首次运行时翻译。

WWDC 展示的古墓丽影虽是翻译应用,但它的性能主要由 GPU 体现。翻译后游戏的渲染仍使用 Metal 指令,因此性能本没有折损,反馈到帧数上便是高帧数运行。而剪辑 4K 用的是 A 系列芯片中的视频硬解码模块,专长于处理 ProRes 视频,所以可以同时编辑多路视频。
可能你会觉得有点反常识,但这次 ARM 的切换与英特尔挤牙膏太久并无直接关联。Mac 这次的芯片变革需要撑得起未来十年,其最优解便是将专精芯片以最优工艺的整合在 Soc 中。
而本文中的一切分析,带来的表象便是:ARM 版 Mac 的运行效率很高。






攻略专题
查看更多-

- 《纳米盒》下载课本点读方法
- 168 2025-03-03
-

- 《纳米盒》更换头像方法
- 211 2025-03-03
-

- 《龙息神寂》不盲者弥希亚技能介绍
- 143 2025-03-03
-

- 《斗战封天》萌新开局攻略及主界面功能介绍
- 212 2025-03-03
-

- 《纳米盒》绑定微信方法
- 125 2025-03-03
-

- 《可口的咖啡》打奶泡方法
- 122 2025-03-03
热门游戏
查看更多-

- 快听小说 3.2.4
- 新闻阅读 | 83.4 MB
-

- 360漫画破解版全部免费看 1.0.0
- 漫画 | 222.73 MB
-

- 社团学姐在线观看下拉式漫画免费 1.0.0
- 漫画 | 222.73 MB
-

- 樱花漫画免费漫画在线入口页面 1.0.0
- 漫画 | 222.73 MB
-

- 亲子餐厅免费阅读 1.0.0
- 漫画 | 222.73 MB
-
